Yo He Visto Cosas Que Vosotros No Creeríais
O cómo Defender una Evidencia Digital, y no morir en el intento.

El hash, como método inequívoco de validación.
Una de las primeras cosas que debe hacer un abogado, cuando intenta dar credibilidad a una prueba documental aportada por éste (como puede ser una pericial informática), es asegurarse de que dicha prueba no tenga fisuras procedimentales, pues lo primero que intentará (o debería intentar) hacer la parte contraria es anular dicha prueba. Un defecto en la cadena de custodia de la prueba, o en la obtención de los datos -entre otras muchas cosas-, puede echar por tierra una muy buena pericial y una inmejorable defensa. Si el caso está basado fundamentalmente en la prueba y ésta tiene algún defecto, la parte contraria no tardará en echarla por tierra; y tendrá medio caso ganado.
Cuando en una pericial han de incluirse evidencias electrónicas, tales como ficheros procedentes de un móvil, o de cualquier otro dispositivo de almacenamiento, es preciso que se garantice que «los ficheros grabados en el soporte digital presentado al Juez, son exactamente iguales a los extraídos del medio analizado».

Ejemplo de codificación hash
¿Y cómo se consigue ésto?. Muy sencillo: utilizando -por parte de los peritos informáticos-, un protocolo de comprobación de datos que garantice que el fichero origen y el destino son idénticos. Estamos hablando en este caso, del algoritmo, o función HASH. No es objeto de este artículo estudiar qué es este palabro; en el Santo Google se pueden encontrar miles de páginas que intentan definirlo, con mayor o menor acierto. En el caso que nos concierne, baste saber que este algoritmo se basa en la lectura de los datos contenidos en un fichero, para generar después un código o cadena hexadecimal de longitud fija, única para ese fichero, de tal forma que, si se modificara «un simple espacio, o un acento», dentro del documento, el cálculo del nuevo HASH produciría una cadena diferente.
Hay varios métodos o algoritmos de codificación utilizados en el cálculo de HASH. Los más famosos son el MD5 y el SHA-1. El «Algoritmo de Resumen de Mensaje 5» -md5-, utiliza un código de reducción criptográfico de 128 bits. O lo que es lo mismo: estudia el contenido del documento a analizar y genera una cadena única, de 128 bits. Sirva como ejemplo el empleado en Wikipedia, para demostrar cómo un simple cambio genera una salida MD5 nueva:
MD5(«Generando un MD5 de un texto») = 5df9f63916ebf8528697b629022993e8
MD5(«Generando un MDS de un texto») = e14a3ff5b5e67ede599cac94358e1028

Algoritmos HASH: La llave que valida la integridad de un archivo.
Como puede comprobarse, tan sólo se ha cambiado el término «MD5», por «MDS» y, sin embargo, la cadena resultante es completamente diferente. El uso de este algoritmo debería bastar para garantizar que los ficheros -tanto el fichero de origen, como el de destino-, son exactamente iguales. El algoritmo MD5 ha sido usado de forma habitual por los Cuerpos y Fuerzas de Seguridad del Estado (en sus grupos especializados de ciberdelincuencia), hasta hace relativamente poco tiempo. Sin embargo, éste procedimiento se ha ido desechando de forma gradual, a causa de un fallo detectado en 1996 por el experto en criptografía alemán, Hans Dobertin. Este analista descubrió un fallo en la generación de las cadenas Hash, de tal manera que, diferentes cadenas de texto podrían llegar a generar la misma cadena Md5. Es lo que se definió como «Colisión de HASH». Como decimos, esto ha provocado que este algoritmo se esté desechando ya, como sistema de autenticación de ficheros o cadenas de texto.
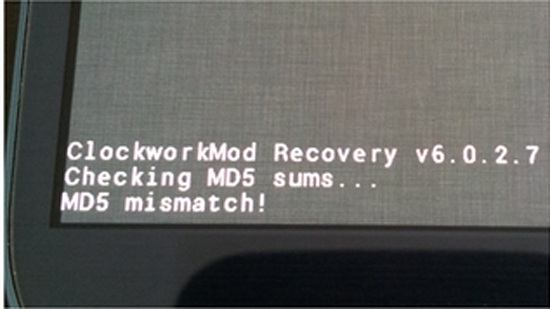
Error en Md5
Por contra, el algoritmo SHA (en sus versiones 1, 2 y 3), o Algoritmo de Hash Seguro, creado por Instituto Nacional de Estándares y tecnología (NIST) de Meryland, se ha postulado como el sistema más seguro de codificación existente hoy en día. Actualmente, el algoritmo más empleado es el SHA-1, que genera una cadena de código de 160 bits. No obstante -y a pesar de su robustez y de la altísima improbabilidad de que puedan generarse colisiones de hash- , en 2004 un grupo de investigadores chinos ya demostró que esta posibilidad existía. Pero a día de hoy explotar este fallo es computacionalmente inviable, aunque el hecho de que -en teoría-, este fallo pueda surgir, está haciendo migrar todos los cálculos de comprobación, al algoritmo SHA-2.
En cualquier caso, y en resumen, es preciso utilizar un algoritmo de comprobación, a la hora de catalogar y salvaguardar las evidencias electrónicas que aportemos. Ya sea MD5, o SHA -en sus versiones 1 ó 2-, el perito tiene la obligación de generar estas cadenas de comprobación en todos y cada uno de los ficheros que quiera presentar en su informe, si quiere que no se dude de su autenticidad. Ya puestos, y aún siendo conscientes de la más que improbable «colisión» que se pueda producir en la generación de los códigos MD5, es preferible utilizar el algoritmo SHA, aunque sólo sea para evitar una contrapericial que ponga en duda la validez de dichos códigos. Por tanto es muy recomendable que tanto los letrados de la defensa, como de la acusación comprueben siempre que, en las periciales aportadas por los técnicos, exista este método de comprobación y validación, como prueba inequívoca que garantice la indubitabilidad de la prueba presentada.
José Aurelio García
Auditor y Perito Informático-Perito en Piratería Industrial e Intelectual-Informático Forense
Vp. Asociación Nacional de Ciberseguridad y Pericia Tecnológica – ANCITE
Informático Forense – El Blog de Auditores y Peritos Informáticos
No hay comentarios